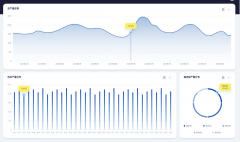

该项目基于GPU物理服务器集群构建云计算平台,通过先进的虚拟化技术实现计算、存储和网络资源的高效隔离与动态分配,为人工智能训练任务提供弹性可扩展的高性能算力服务。平台采用多层次虚拟化架构设计,在硬件资源层通过IB(InfiniBand)网络虚拟化技术构建低延迟、高带宽的通信网络,为分布式训练任务提供优异的网络性能保障。在计算资源层,采用GPU穿透(GPU Passthrough)技术实现物理GPU设备的直接映射,使虚拟机能够获得接近原生性能的GPU算力,支持按需分配和动态调度。在存储层,集成Ceph分布式存储系统与OpenStack云平台,构建高可用、高吞吐的存储服务体系,满足AI训练对海量数据的高速存取需求。平台通过智能调度算法实现计算资源的优化配置,支持多种深度学习框架的运行环境快速部署,并提供完善的监控和运维管理功能。该解决方案显著提升了GPU集群的资源利用率,为大规模AI模型训练提供了稳定可靠的云计算基础设施支撑。
联系我时,请说是在杭州含情网络技术有限公司看到的,谢谢!